Look-alike简介
Look-alike是在线营销活动中常用的一种技术,目的是根据广告主提供的用户,帮助其进行人群圈选。Look-alike的输入是一个user列表(可以是user id 或者电话号码等id标识),这个user列表可以是广告主上一次活动的人群,可以是广告主的已有用户中高净值人群等等。这个输入人群列表有个专有名次叫做“种子用户(seeds)”。而Look-alike的输出还是一个user列表,与输入user列表存在强关联(相似)的用户群。
在Look-alike中,我们要考虑很多因素
- Performance: 效果是每个模型或者算法都要关注的方面,例如准确率、召回率、AUC等指标都可进行衡量;
- Scalability: 模型可以处理的数据规模,这直接关系到算法的可用性,是否可以应用在大数据集上;
- Real-time: 有些业务是要关注实效性的,如果是n+1的任务模型大可以花费10几个小时输出结果,但如果业务要求实时,那么就要对算法提出更高的要求。
Look-alike 分类介绍
Look-alike技术根据具体实现的算法,可以大致分为如下集中:基于相似度(Similarity-based), 基于相似度扩展(主要以Yahoo提出的方法为例), 基于回归模型(Regression-based), 基于Attention深度模型(Attention-based)
基于相似度(Similarity-based)的Look-alike
Similarity-based是最直接的一种实现Look-alike的方法,其中主要是基于user-2-user之间的某种距离大小来衡量用户之间的相似度。主流的相似度计算方法包括:针对连续值的余弦相似度(Cosine similarity)以及针对离散值的(Jaccard similarity):
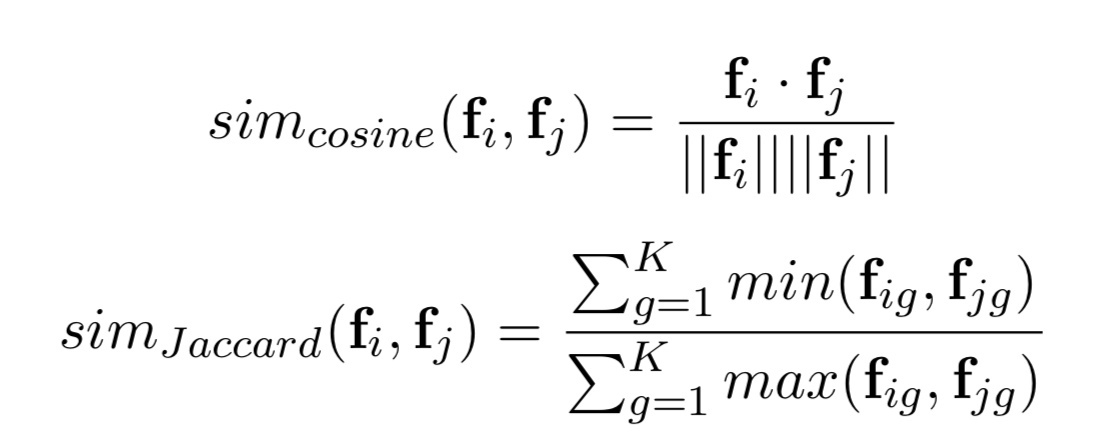
两个user之间的相似度计算之后,那么怎么计算某个用户对seeds整体的相似度呢?一个用户u1与seeds整体的相似度可以总很多角度来考虑:
- 最大值Max:利用u1与seeds中相似度最大值作为u1与seeds的相似度 sim(u1,seeds)=Max(sim(uj,seeds))
- 平均值Mean:利用u1与seeds中每个用户的相似度去均值作为整体相似度 sim(u1,seeds)=Mean(sim(uj,seeds))
- 基于概率:该方法要求用户之间的相似度在[0,1]之间。通过不相似度反向得到相似度。
-
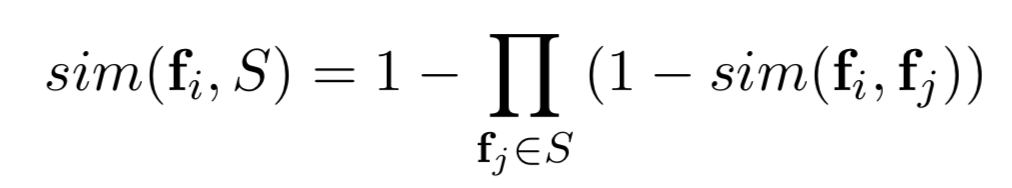
总结: Similarity-based非常简单,但是复杂度过高,很难在大规模数据集上进行。如果候选集的用户量是N,种子用户量是M,计算相似度用到的特征维度是k的话,那么这种算法的时间复杂度就是O(kMN)。
基于回归(Regression-based)的Look-alike
这里将Look-alike看作一种二分类任务,采用如LR的二分类模型对其进行建模。 其中种子用户”Seeds”一般作为正样本,至于负样本的选择存在几种方式:
- 所有非种子用户:这是最简单的方法,但并不是最好的方法。因为潜在兴趣用户可能存在其中
- 非种子用户+限制:比如非种子用户中存在曝光、点击、浏览等行为但是没有转化的用户。但是对于新广告主或者新产品,存在冷启动(cold-start)问题
其实这个问题严格意义上属于PU Learning问题,这里不进行扩展。
总结: Regression-based的思路根据用户特征极大化seeds用户的概率,对应模型很多如LR、MF等。但是该方法依旧存在不足,每次营销活动都需要定制化训练模型,每次增加item都要重新训练模型,严重影响实时性。
基于相似度扩展的Look-alike
其中比较代表性的就是Yahoo雅虎提出的方法:A Sub-linear, Massive-scale Look-alike Audience Extension System。 该方法首先利用局部敏喊哈希Locality Sensitive Hashing (LSH)来优化similarity的计算并构造全局图,目的是粗粒度滴筛选候选集,之后根据特征重要性对候选集进一步排序筛选。
局部敏喊哈希Locality Sensitive Hashing (LSH)
LSH可以看作是一种简化计算similarity的方法,大体可以分为两个步骤:
-
- 利用一组哈希函数,将user的特征向量转化成一组signature,转化并不是拍脑袋来的,需要具备两个特征:(1)特征向量相似则转化后的signature也要很大概率相似;(2)如果采用H个hash函数,则会产生H个signature,那么signature矩阵的维度就是H,要远远小于特征向量的维度。
-
- 根据signature形成用户的聚类clusters,对于每个user都至少属于其中一个cluster。这样给定一个user,可以直接根据哈希函数转化,进而将user指派到相应的clusters中。根据signature构造的clusters具有这样的性质:同一个cluster中的用户具有很高的相似度。
因此,LSH不需要对用户之间进行两两比较,从而极大的优化了寻找相似用户的过程。对于特定的相似度方法如cosine和Jaccard等,都存在一种hash函数,经过hash转换后依旧保持相似性。下面以Jaccard相似性和MinHash为例
最小哈希MinHash
在LSH中的hash技术目的就是减少用户特征空间,同时保持原有的相似度关系。对于Jaccard相似度来说,对应的hash就是MinHash:
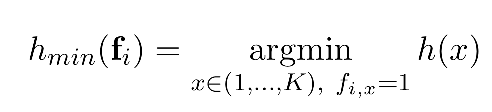
其中,fi是用户i的K-dimensional的特征向量,x是fi中特征的index。哈希函数h(x), [h : (1, . . . , K) → R]将特征的index映射到一个随机数。而函数hmin(fi)定义为具有最小hash值的特征index,这里的hmin(fi)就叫做哈希signature。为什么这样定义MinHash呢,因为只有这样定义才满足:两个用户的MinHash值相同的概率等于他们之间的Jaccard相似度。证明过程在后面,这里先给出结论:
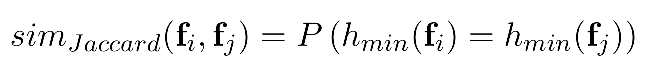
换种表述方式:如果两个用户的Jaccard相似度为r,我们利用H个MinHash函数对两个用户分别进行转换,这样每个用户会形成H个signature,那么两个用户相同的signature数量应该为H*r个。
MinHash与Jaccard证明
对于Jaccard相似度,只需要考虑binary特征即可,因此假设四个集合分别为:S1, S2, S3, S4,对应的元素是a,b,c,d,e,如下图:
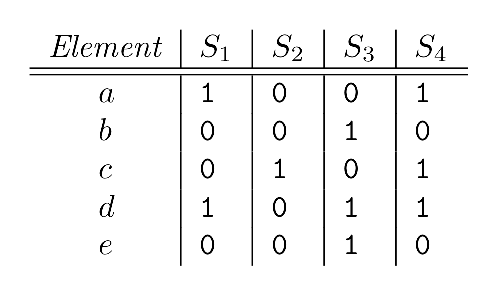
首先修改一下MinHash的定义(其实是一样的,后面会说明):按照行进行随机扰动(permutaion)之后,从上到下 每一列(每一个集合)的第一个等于1的元素所在的当前行号定义为MinHash的值。如下图所示:
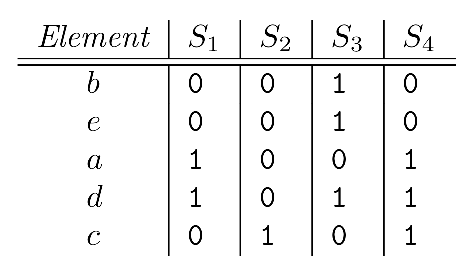
按照定义,上图中的四个集合的MinHash分别为:MinHash(S1)=2, MinHash(S2)=4, MinHash(S3)=0, MinHash(S4)=2
接下来证明:“两个集合,基于随机扰动的MinHash值相等的概率=他们之间的Jaccard相似度”。只考虑两个集合S1和S2,根据每一行两个元素是否等于1,可以分为三种情况:
- Type X:S1和S2都等于1对应的行,行数记为x
- Type Y:S1和S2中只有一个等于1,另一个等于0 对应的行,行数记为y
- Type Z:S1和S2都等于0的行
对于稀疏矩阵来说,大部分情况都属于Z,但其实Jaccard的计算只涉及到X和Y,与Z无关,因此可以忽略Z。杰卡德相似度很容易计算Jaccard(S1,S2)=x/(x+y)。
至于MinHash相等的概率,我们这样考虑:
- 随机扰动之后,不考虑Type Z的情况下,从上到下遍历,首先遇到Type X的话,那么一定:MinHash(S1)=MinHash(S2),因为Type X说明两者都为1,且属于同一行,因此一定相等
- 随机扰动之后,不考虑Type Z的情况下,从上到下遍历,首先遇到Type Y的话,那么一定:MinHash(S1)!=MinHash(S2),因为一个MinHash是当前行号,另一个MinHash一定在下面的行号
接下来我们考虑上面两种情况的概率:
- 首先遇到Type X的概率为:x/(x+y)
- 首先遇到Type Y的概率为:y/(x+y)
首先遇到Type X 则 MinHash相等,因此MinHash相等的概率=首先遇到Type X的概率x/(x+y),这与Jaccard相似度正好相等。从而证明了上面的“两个集合,基于随机扰动的MinHash值相等的概率=他们之间的Jaccard相似度”。
但是还存在一个疑问:两种MinHash定义之间怎么统一,答案就是利用Hash映射函数H(x)来模拟随机扰动。因为大规模数据的扰动是非常耗时的,因此可以利用利用哈希函数H(x)来进行模拟,H(x)是一个映射函数,将[0,k]映射到[0,k]之间,当然会存在碰撞问题,但只要k取得足够大,碰撞问题就可以忽略不及。
举个例子,如果我们定义两个Hash映射函数h1(x)=x+1 mod 5, h2(x)=3*x+1 mod 5,那么结果如下图:
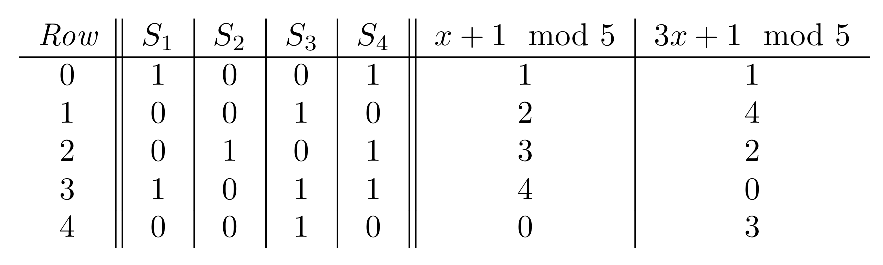
其中最后两列Hash映射之后值就代表随机扰动之后对应的新行号h,对于每一列集合S,只要(在等于1的行中)找到最小的行号h,就得到了MinHash,因此Signature签名矩阵为:
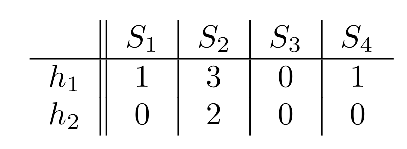
LSH
利用H个MinHash函数产生的Signature就是H-dimensional的,因此所有用户的Signatures就形成了一个N*H的矩阵,叫做signature矩阵。其中N表示用户数量,如果用户特征向量维度是K的话那么H«K,因此signature矩阵可以看作是用户特征矩阵的降维结果。
利用H-dimensional的signature矩阵,LSH可以将用户聚类成同buckets,从而快速找到相似用户。存在很多中聚类方法,其中最流行的是“AND-OR”规则:
-
- 将H维度分为b个bands。这样每个band都包含r个signature的维度,且b*r=H
-
- 每个band都会对应多个bucket,只有用户在某个band中的所有r维signature都相等,他们才会被cluster进同一个bucket
-
- 一个用户会进行b次cluster,从而进入b个不同的bucket
-
- 对于一个新用户,只要被cluster进某个bucket(bi),那么bi中的所有用户都成为该用户的候选用户。这个用户量要比全量用户小的多。
-
- 其中b和r是超参数,需要根据实际情况进行调整
经过基于MinHash的LSH之后,每个用户ui都会生成一个bucket id列表。对于给定的一个Seeds人群,其中每个user都存在相应的哈希signature,那么每个用户都会对应一个bucket id列表,将这些buckets中的人群union在一起,就形成了Seeds的候选集合。
定制化排序模型
经过上一步的LSH,可以得到Seeds的候选集,这部分人群数量明显少于全量用户,而且具有一定的内在相似度。接下来要做的就是对这部分用户进行排序,之后根据要求选择top N用户作为输出。至于如何排序,其实存在很多种方法,Yahoo综合考虑效果、实效性等因素,选择根据特征权重来进行排序。
对于特征选择(feature selection),例如逻辑回归LR、决策树等算法都可以完成,但是基于效率考量Yahoo采用了一种非迭代(non-iterative)的方法:信息值information value (IV)
首先定义:S表示Seeds用户,U表示候选集合。pj表示Seeds中存在feature j的用户比例
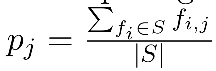
候选集中存在feature j的用户比例:qi
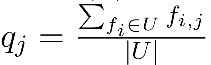
通过单变量分析(univariate analysis)来计算特征重要性的方法有:互信息(mutual information)、信息增益(information gain)、和信息值(information value, IV)等。这些方法都假设特征之间是相互独立的,而且Yahoo实验发现这些方法的效果非常相似,因此采用IV进行介绍。
对于binary的特征j来说,基于IV的重要性可以通过如下公式度量:
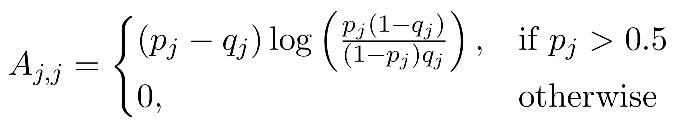
其中pj > 0.5说明:只有”positive”的特征才会被考虑,这些特征在Seeds中的重要程度要高于在候选集U中的重要程度。根据IV值排序,值越大的feature则具有更强的预测能力。同时可以将特征排序结果展示给广告主,提供模型的解释能力(transparency)。
有了上述IV矩阵A之后,Yahoo采用如下公式计算每个候选用户对于改次营销活动c的价值分:
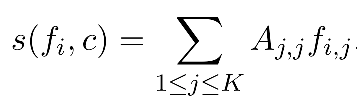
其中fi代表该用户的特征向量,这个值并不是[0,1]的,因此可以通过sigmoid函数进行转换之后作为结果。
小结:LSH提供了一种缩小候选集的方法,同时保持了内在的相似性。为每个任务定制化模型是很耗时的,虽然Yahoo采用了非迭代的方法IV来计算用户得分,极大的提高了效率,但是每次任务都要定制化,依旧无法实现real-time的要求。
基于Attention的Look-alike:Real-time Attention Based Look-alike Model for Recommender System
这是腾讯最近提出的一个基于deep leanrning的Look-alike系统,采用了当前比较热的attention,能够满足Real-time的要求。
1. 背景
1.1 业务背景
- 马太效应Matthew effect:在微信的“看一看”场景中,存在大量的长尾文章,这些文章可能是最新的新闻,但是去缺少用户和特征,因此导致模型无法推荐这类文章。而一些热门的文章却会一直被推荐,从而形成了推荐系统的马太效应。
- 多样性diversity:解决马太效应的有效方法就是提高推荐结果的多样性,让最新的新闻,长尾的文章也有机会触达人群。
- 实时性Real-time:微信“看一看”场景对实时性要求极高,不可能产出了一篇文章后,线下花上几个小时训练一个LR模型,之后在进行预测。因此要求模型能够实时在线预测。
1.2 模型背景
- Attention机制:Attention是2015年被提出来的,在NLP领域大放光彩。Attention具有在繁多信息中自动focus到重点的能力,而且Attention可以实现并行,一定程度上可以替代LSTM等循环神经网络,提高模型效率。Attention的具体介绍可以参考Attention总结。
- Embedding:主要分为User Embedding和Item Embedding两个方面,而这篇文章主要用到的是User Embedding 作为 User Representation,在look-alike模型中作为输入。该文是对Youtube DNN模型作为基础,进行了一定的调整,最后目的是获取user embedding。
2. 模型
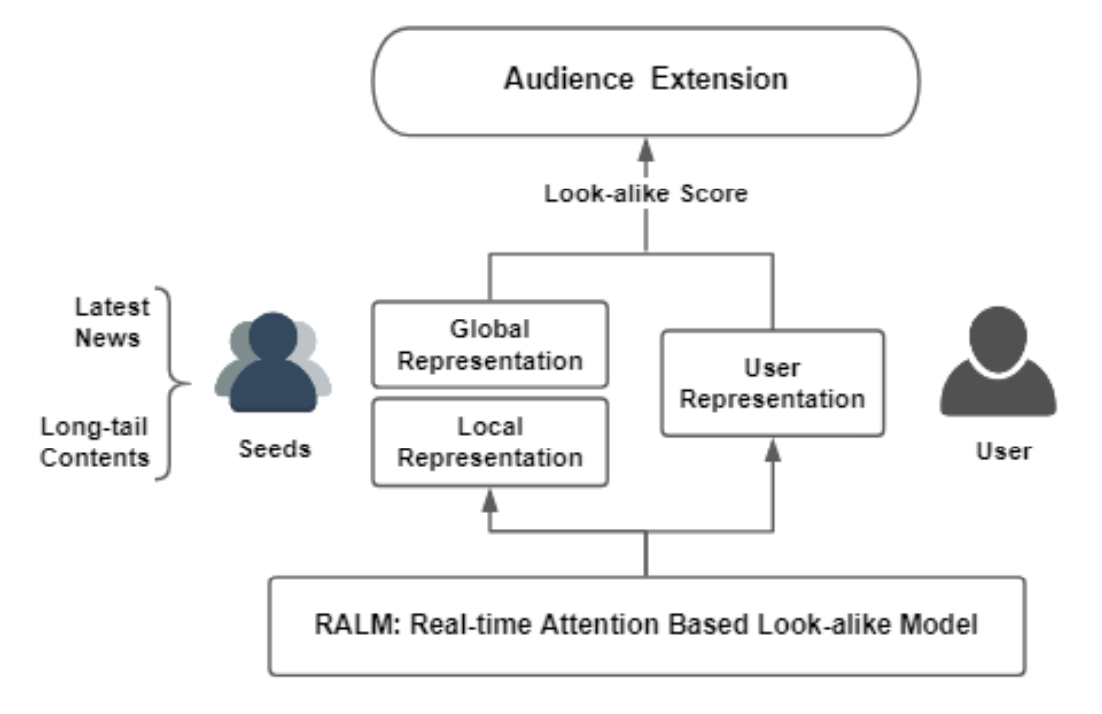
首先看一下整体模型结构,存在两个输入:
- 左侧:该item的Seeds用户,其实是Seeds用户的clusters,不需要实时更新只要定时异步更新即可,后面会详细介绍
- 右侧:候选集的某个用户,因此模型会遍历候选集,为每个候选集用户进行计算
之后根据模型参数和模型结构计算两种Attention,进而计算look-alike得分,最后根据得分排序,输出扩展人群。
模型整体大致可以分为三个主要部分:离线训练、在线数据处理、在线实时预测
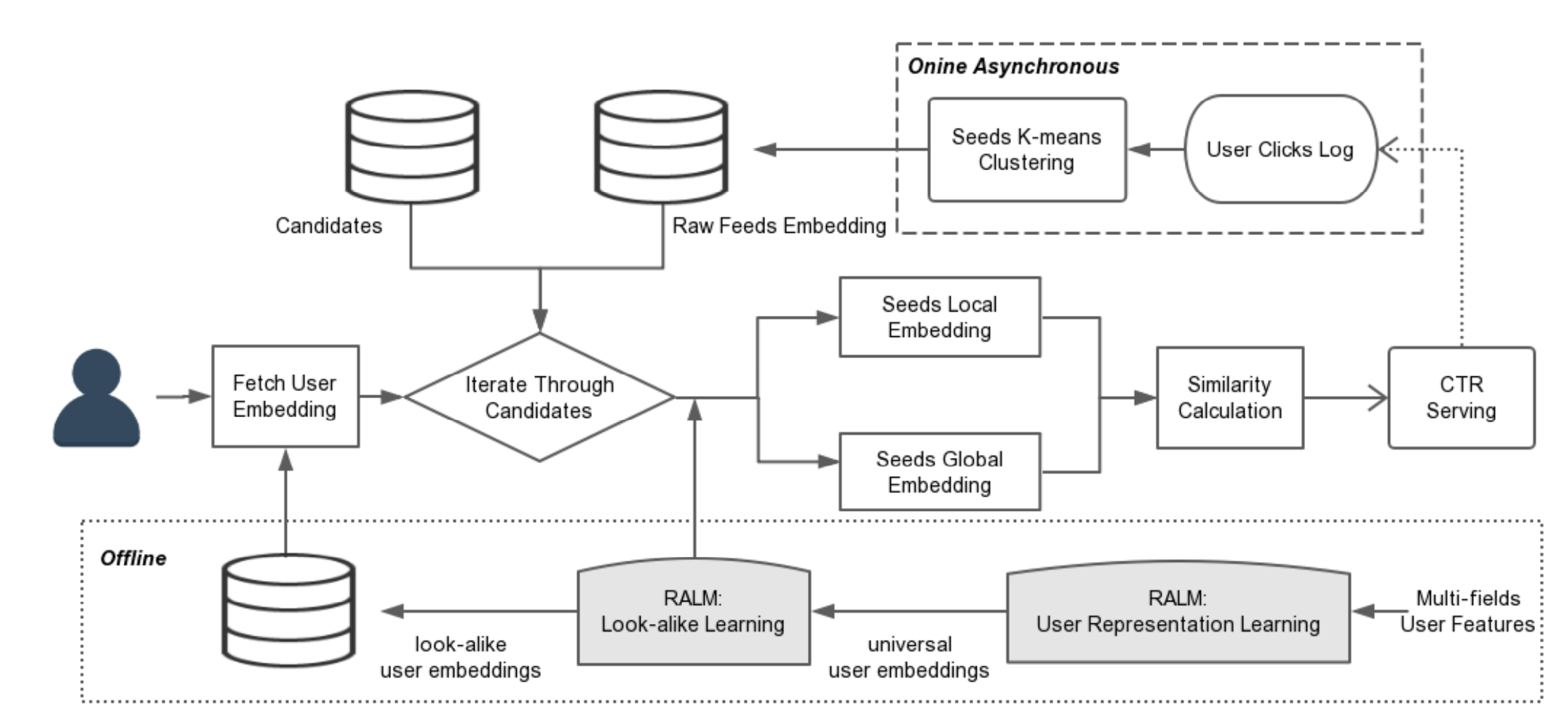
- 最下面离线训练:表示离线部分Offine,主要包括两个模型的训练:User Representation Learning(user-item模型)和Look-alike Learning(user-user模型)
- 最上面在线处理:代表Seeds的clusters结果的异步更新,这是线上定时完成的。因为用户对文章的浏览行为时刻发生,因此Seeds用户是时刻增加的,但是又不可能每次发生行为都去更新clusters,文章采用每5分钟更新一次clusters的策略。这样不会影响模型的实时性。
- 中间在线预测:遍历候选集,根据模型逐层计算的过程。因为在这之前,模型输入和模型参数等都已经准备就绪(Offine训练搞定了User embedding和模型参数,而定时更新clusters搞定了Seeds端的输入),因此可以实时进行预测。
2.1 离线训练 之 User Representation Learning
这部分是一个user-item的deep learning模型,文章采用的整体策略是类似于双塔的结构,左侧user tower的目的是得到user embedding,右侧item tower的目的是得到item embedding,最后将两个embedding向量进行点乘(dot),最后一层softmax进行分类。这里的item embedding比较简单,随机初始化后随着模型一起训练就可以,重点部分在于左侧的user部分。
2.1.1 User embedding
存在很多模型结构可以得到user embedding,这篇文章借鉴Youtube DNN模型,因此有必要对Youtube DNN模型进行简要介绍:
-
- 将行为分为多个fields,并且每个field内部各个行为的embedding向量长度相同
-
- 对每个field做average pooling,得到每个field对应的一个向量
-
- 再将所有fields的向量concatenate到一起
-
- 经过若干层MLP layer之后,输出的就是user embedding
这里的第3步骤concatenate操作对应下图中的”Merge Layer”,但是本文对Youtube DNN做了调整,在”Merge Layer”这一层并没有采用concatenate的方式,而是采用的Self-Attention机制。
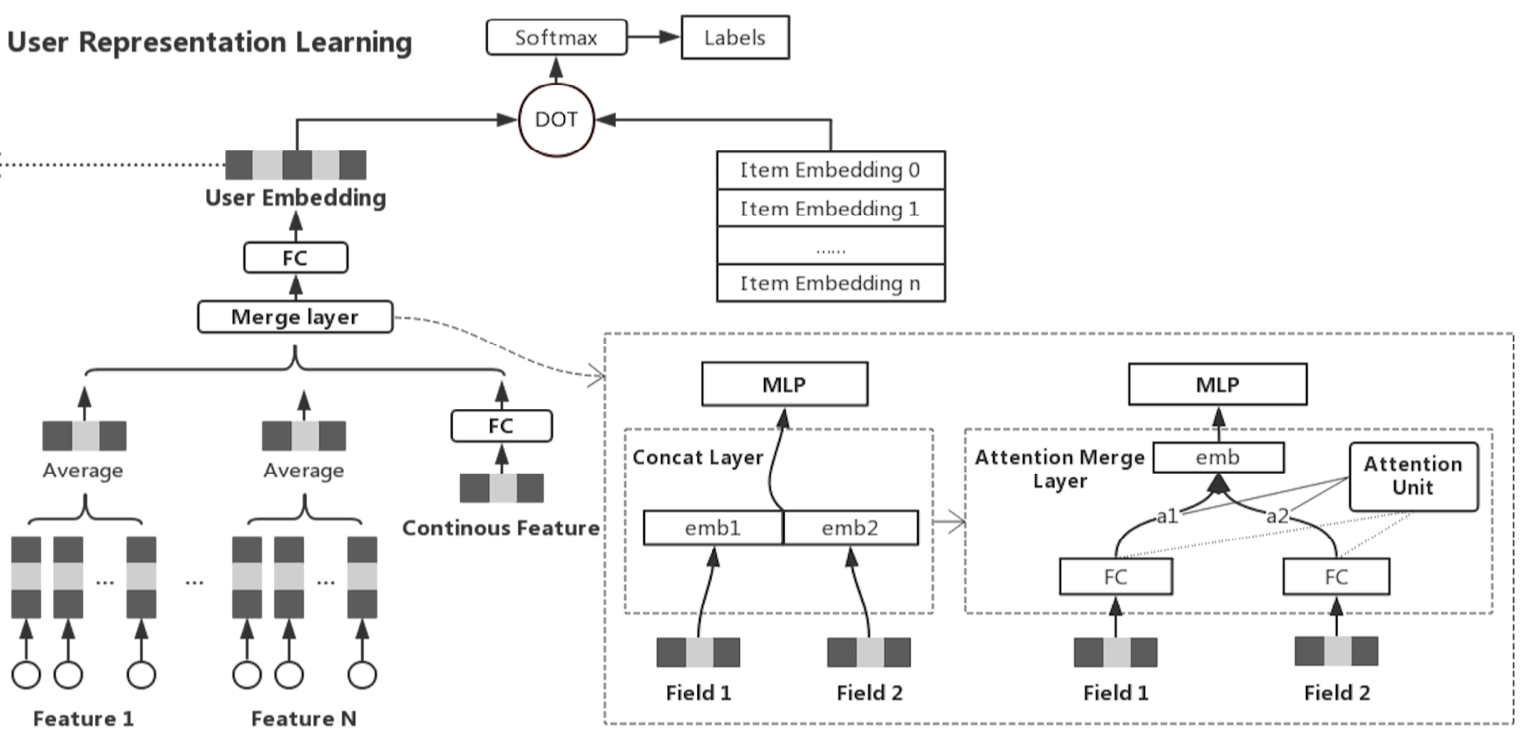
原因:作者发现,如果简单将多个fields进行concatenate的话,那么相当于强制模型利用同一个分布去学习不同的fields(forces all users’ interest to be learned into the same distribution)。这样会导致:只有少数与用户interest关联较强的fields对用户产生影响,这部分特征过拟合,而其他特征又会欠拟合。也会导致权重矩阵非常稀疏,因为多数fields影响较小。因此,本文采用Attention机制解决这个问题,因为Attention可以学习到关于用户的个性化的fields权重,而不是同一个分布。
Attention的机制和权重计算方式很丰富,这里只介绍本文采用的方法,如果想了解详细的Attention可以参考Attention总结。
假设存在n个fields,对应的向量长度都是m,那么每个向量h ∈ Rm,之后在第2个维度上将这些向量concatenate到一起(罗列在一起),就形成了矩阵H ∈ Rn×m。权重向量a的计算采用如下公式:
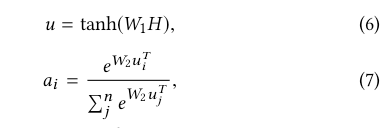
其中W1 ∈ Rk×n , W2 ∈ Rk都是权重矩阵,k表示attention单元的size。u ∈ Rk*m,最后得到a ∈ Rn表示n个fields的权重。之后将权重a与原始fields矩阵merge到一起,就得到了最终结果 M ∈ Rm:

将M作为MLP layers的输入,最后即可得到user embedding。如上文所属,最后将user embedding和item embedding进行dot之后softmax分类,模型就搭建完成了。
2.1.2 negative sampling
采样
类似与word2vec的操作,本文同样采用负采样negative sampling代替传统的softmax。由于随机抽样会不符合实际情况,因此本文采用了一种类似与谷歌NEC Loss的方法:首先根据item的频率进行排序,之后根据如下公式计算概率:
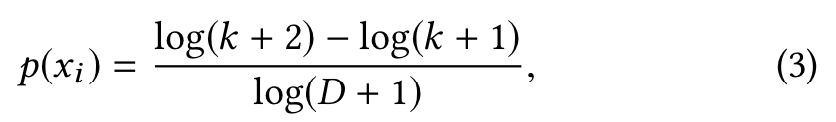
其中xi表示第i个item,k表示第i个item的排序rank,D表示所有items中最大的rank,最后结果p(xi)表示第i个item被抽中作为负样本的概率。为了避免部分活跃用户支配Loss的情况,本文对样本进行如下限制:
- 每个用户最多50个正样本,减少少量活跃用户的影响
- 正负样本比例设为:1:10
概率
| 采用softmax函数来计算用户u对item的概率,如下公式,u代表用户向量,xi代表item向量,结果P(c = i | U,Xi)表示用户U对item Xi的概率: |
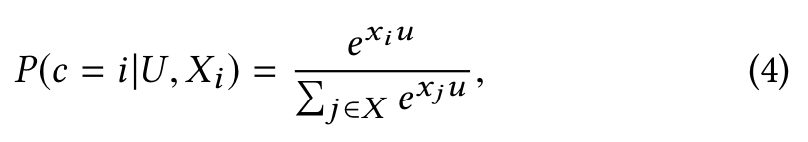
损失Loss
本文采用的是cross entropy loss,yi ∈ {0, 1}
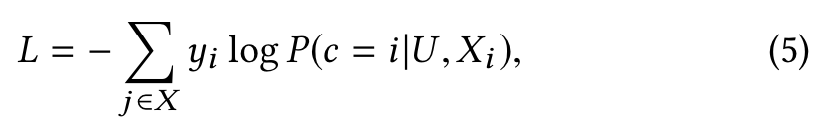
2.1 离线训练 之 Look-alike Learning
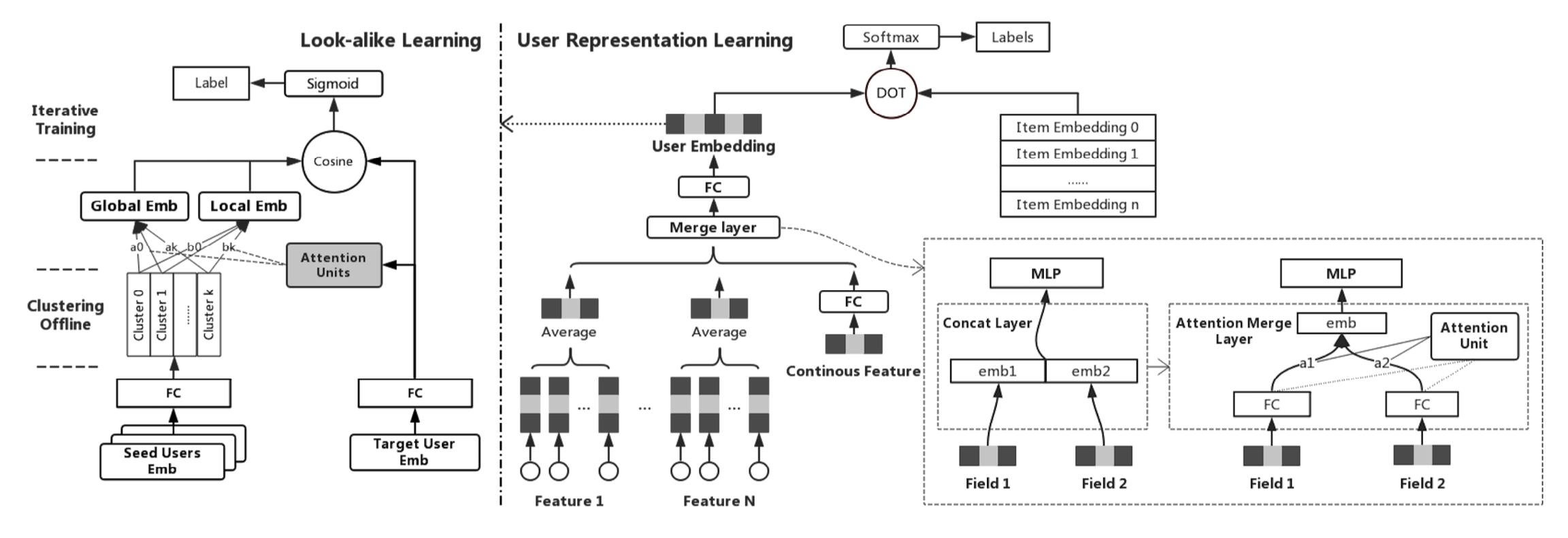
首先看结构图,Look-alike模块的输入就是上一步得到User embedding。Look-alike模块采用的典型的双塔模型,左侧是Seeds tower,右侧是tartget tower。
2.1.1 target tower
右侧的target tower其实就是user embedding,比较简单不需要做任何处理。
2.1.2 seeds tower
2.1.2.1 k-means cluster
由于Seeds的用户量相对较大,会严重影响后面attention层的效率,因此这里采用k-means聚类的方法,将Seeds聚成k个clusters,将k个clusters作为 seeds tower的输入。
- 减少模型复杂度:k提前确定,k个clusers存在内存中,极大减少了模型复杂度
- 线上预测clusters在线异步更新:由于浏览点击等行为时刻发生,因此Seeds时刻都在发生变化,但是不需要实时更新clusters,只要定时更新即可(每隔5分钟更新一次)。
- Iterative training:因为训练时模型反向传播,会更新user embedding值,因此每个epoch结束都要重新进行cluster,得到最新的clusers。
2.1.2.1 global attention和local attention
其实文章中的global attention就是selt-attention,而local-attention就是普通的attention,由于attention的文章比较多,这里不做详细介绍,有兴趣可以参考attention介绍
2.1.2.3 Loss
只要Look-alike模块采用的Loss就是比较常用的sigmoid cross entropy:
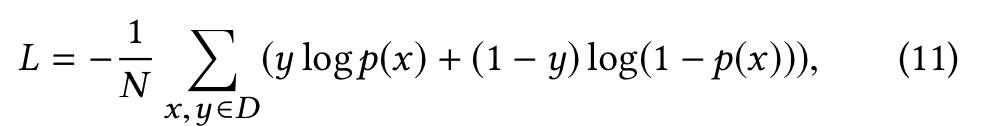
其中D表示训练集,y{0, 1}表示label, p(x)表示双塔计算cosine并且经过sigmoid的预测概率得分。