layout: post title: ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation 详解 subtitle: attention recommendation date: 2020-01-21 author: ZhangWenXiang header-img: img/bg-ai-dark1.jpeg catalog: true tags: - 推荐系统 - attention - 行为建模 - 深度学习 - 异构行为 —
ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation 详解
一、简介
- 这是阿里巴巴和北大联合发表的一篇论文,在电商环境中,用户会存在多种行为:浏览、购买、收藏商品,领取、使用优惠券,搜索关键词等等。
- 由于attention具有抓取序列间的内在关系的能力,因此利用attention来对用户不同的行为进行建模,致力于更全面的融合用户的不同行为。
- 本文针对异构的行为,提出的是一个通用框架,下游任务可以根据业务场景自行设计。
二、模型框架

模型主要分为四个部分:
- Raw Feature Spaces:原始特征,对应多种不同行为
- Bahavior Embedding Spaces:embedding特征,对应多种不同行为
- Latent Semantic Spaces:语义空间,将行为映射到多个语义空间
- Self-Attention Layer:attention建模行为之间的潜在关联
- DownStream Application Network:下游任务
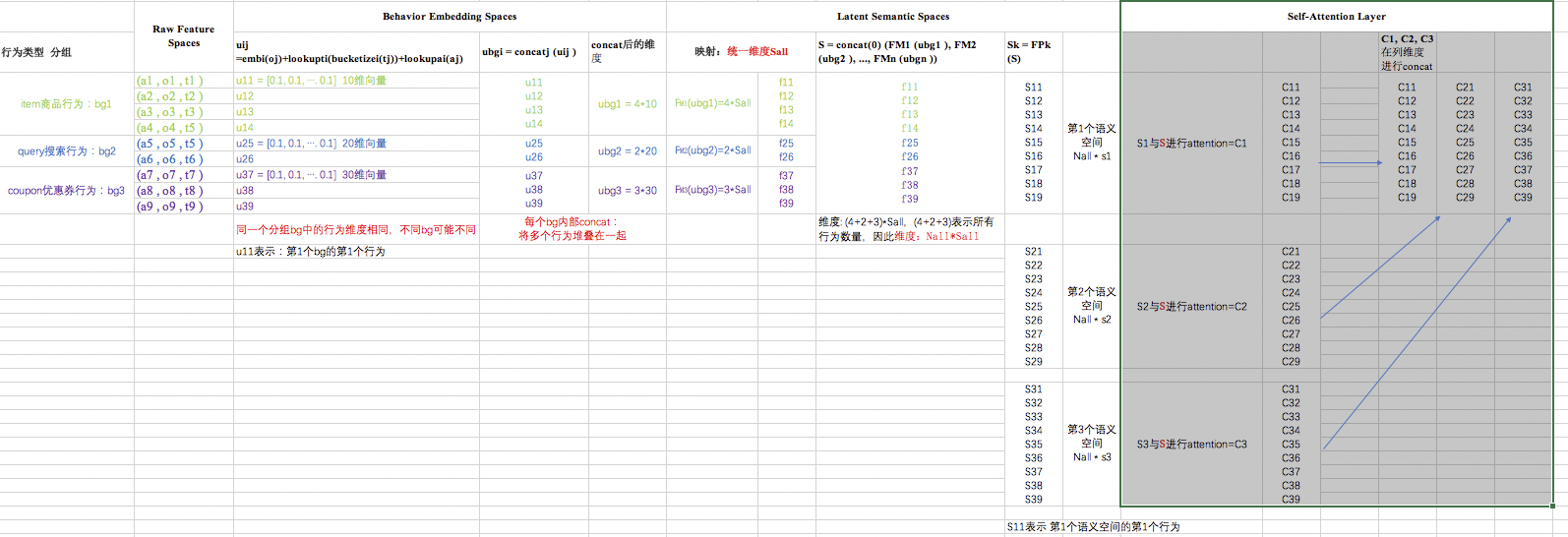
以下是过程举例图解:每个u11,s11,f11等都是行向量如[0.1, 0.2, …]

1、Raw Feature Spaces
这一部分主要是对原始特征进行介绍
- 行为元祖:{a, o, t}, a表示行为类型, o表示行为对象, t表示行为发生时间
-
用户的行为序列: U ={(aj , oj , tj ) j = 1, 2, …, m} - 行为分组:根据o对行为进行分组,G = {bg1, bg2, …, bgn},其中每个bg没有重合且并集就是全集G。举例:对商品的行为组成第一组bg1,搜索相关行为bg2,优惠券行为是bg3。
具体过程如下图:每个组内行为不同,embedding size也可能不同

2、Behavior Embedding Spaces
这部分其实就是根据原始特征,获取相应的embedding表示
- 首先是每个行为的特征embedding:
uij =embi(oj)+lookupti(bucketizei(tj))+lookupai(aj),将商品、时间和行为三种类型的embedding进行聚合
- 商品:embi(oj)就是物品oj对应的embeding表示,可以随机初始化
- 时间:根据时间戳tj获取时间间隔gap,之后将时间间隔映射到以下分桶中[0, 1), [1, 2), [2, 4), …, [2k, 2k+1),这样就转化为类别特征了。接下来就可以直接类似onehot根据lookup得到embedding表示,这里注意不同的bg中,时间的lookup的embedding并不共享。
- 行为:行为a本身就是类型特征,所有类似onehot直接loopup就可以了
- 接下来对行为进行分组
B = {ubg1,ubg2,…,ubgn}, 每个组的向量有组内的行为向量uij聚合而成 ubgi = concatj (uij )
这里需要是注意是根据哪个维度concat(参考下图例中的维度)
语言苍白的,还是看图吧:

- 不同的bg中涉及到相同的特征可以共享embedding,但是关于时间的则不共享(因为每种行为的时间影响不同)。
3、Latent Semantic Spaces
3.1 向量编码 S
- 由于每组中行为的最终embedding长度不一,因此首先要通过映射函数FMi(Ubgi)将每个ubg映射到相同的维度 Sall:
- encodding vevtor: 所有的bg向量 concat到一起,获得固定长度的编码向量
S = concat(0) (FM1 (ubg1 ), FM2 (ubg2 ), …, FMn (ubgn )) 注意是在哪个维度上concat(见图)
语言是苍白的。。。还是看图吧:

3.2 语义空间
- Sk = FPk(S):对编码向量S,采用多个映射函数FPk(),就可以映射到多个不同的空间,这部分很简单不赘述
3、Self-Attention Layer
每个语义空间Sk,分别与向量编码S进行attention计算,其中Sk用户生成query, S则用户生成key和value。
- score计算
Ak = softmax(a(Sk, S; θk))
a(Sk, S; θk) = SkWkST - attention向量计算 Ck =AkFQk(S)
- 多个attention向量进行concat,获取网络最终的向量表示,之后在全联接F即可
C = F(concat(1) (C1 , C2 , …, CK ))
论文总结
- 特征处理(raw feature 和 behavior embedding):行为分组、时间间隔编码等方法,对用户的行为信息进行embedding。
- 统一编码:不同行为分组的特征concat到一起,形成一个最终的编码向量 S = concat(0) (FM1 (ubg1 ), FM2 (ubg2 ), …, FMn (ubgn ))
- multi-head attention 论文里面讲的的映射到多个语义空间,其实就是muti-head attention,在公布的代码中也是这样实现的 https://github.com/jinze1994/ATRank
其实就是针对编码向量S进行多头的attention操作
从这个角度理解,论文就简单多了,流程例图也可以简化为:
