embedding技术总结
一、矩阵分解类方法
- 以movielens的电影评分为例,矩阵中的数据代表用户对电影的喜爱程度,其中大部分数据处于缺失状态。
- 矩阵分解类方法都是致力于将该矩阵分解为两个矩阵,一个矩阵维度m×k代表用户embedding,另一个矩阵n×k代表电影embedding。

SVD
svd就是大名鼎鼎的奇异值分解,公式如下:

-
奇异值分解将矩阵分解为三个矩阵,其中U叫做左奇异向量,V叫做右奇异向量,中间的是奇异值构成的对角矩阵,并且每个奇异值非负且逐渐减小,因此可以从k个奇异值中选择最大的d个来降低矩阵分解的维度。
-
左奇异向量U是矩阵M×MT(维度m×m)的特征向量,表示用户的embedding表示;而右奇异向量V是 MT×M(维度n×n)的特征向量,因此表示item的embedding表示
-
MT×M的特征值与奇异值的关系:特征值=奇异值的平方
虽然公式简单,易于理解,但是奇异值分解存在很多缺点,难以应用
- 矩阵必须是稠密的,即矩阵里的元素要非空,否则就不能运用SVD分解。因此要现对矩阵进行粗糙的填充(例如均值填充),之后才能进行SVD分解。
- 计算复杂度和空间复杂度都比较高,因此现在很少用SVD来做embedding
Latent Factor Model(LFM)
LFM也被叫做Matrix Factorization(MF)
LFM是根据SVD进行修改而来的,我们要得到embedding表示,因此分解的矩阵不一定非要具备经典奇异值分解的正交矩阵性质。LFM独辟蹊径,只针对原矩阵中的真实值进行建模,训练模型中忽略缺失值。
- 每个用户对应一个向量pu
- 每个item对应一个向量qi
- 用用户u的向量和item i的向量点积来表示矩阵中的元素r(u, i)
- 损失函数为平方损失
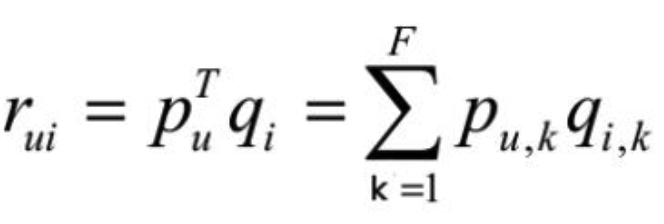
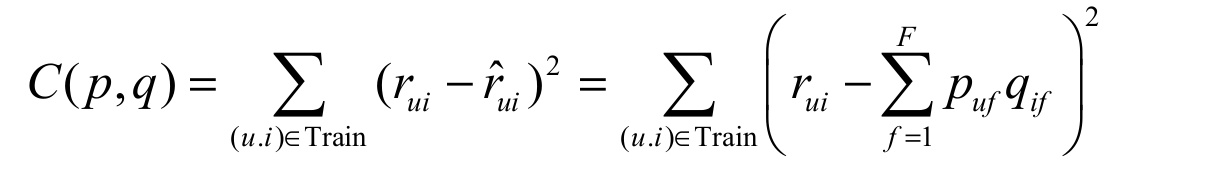
- 优化算法:交替最小二乘法(ALS)或者梯度下降法(GD)
- 梯度下降: 用户u的向量的f分量的梯度如下:

item的梯度与上述类似。
- ALS: (1)固定p,之后对q求导等于0,求出q的解析解; (2)同样固定q,对p求导等于0,也可以求出q的解析解; (3)循环1和2从而更新p和q,直到收敛或者最大迭代次数
贝叶斯矩阵分解(Bayesian Probabilistic Matrix Factorization, BPMF)
从贝叶斯概率的角度来重新思考矩阵分解MF,矩阵元素r不再等于p×q,而是服从以p×q为均值的正态分布;而且p和q也都服从于正态分布。
- 贝叶斯准则:后验正比于似然与先验的乘积
- 推导并写出所有参数的后验分布
- 根据后验分布采样和更新参数
BPMF比较复杂,详细数学推导可以参考下面文章[1]
二、word2vec类模型
Word2Vec
Word2Vec是谷歌的杰作,开启了万物皆可embedding的时代。。。
Word2Vec主要提出了两种方法Hierarchical Softmax和 Negative Sampling,其中负采样用的更多一些。Word2Vec虽然源于NLP但却高于NLP,已经被用到了很多其它领域,这里就不多介绍了,相信都比较了解,直接祭上论文吧(google 2013)
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Words and Phrases and their Compositionality
Item2Vec
微软2016年发表的一篇论文,这个论文并没有太大的理论创新,但是应用性极强,将word2vec应用于推荐广告领域,现在也有一些公司将这种方法用于召回场景中,可以说极大的拓宽了word2vec的应用范围。
Airbnb
这篇论文是Airbnb 2018年在kdd发表的,理论创新较少,但确与业务紧密结合,是工程领域里面具有很大影响力的论文。
- 明确拒绝的item放入negative sample
- global context:将最终预定的listing作为全局正样本,在所有滑窗中都参与训练
- 负采样:专门增加一个负采样的逻辑,就是从与central listing相同城市的集合中采样
- 聚合成listing_type和user_type:为了解决数据稀疏问题,将listing和用户根据固定的属性(用户年龄、身高等;房子尺寸、位置等)进行聚合
- user和item向量在同一空间:在同一向量空间下的user_type和listing_type embedding,这一点很有意思,这样user和listing就可以直接计算距离了。
Real-time Personalization using Embeddings for Search Ranking at Airbnb
三、Graph Embedding
word2vec相关的方法本质上就是一种sequence embedding,主要对sequence序列的共现进行建模。而Graph Embedding作为另一种embeddig方案,在研究和工程领域的应用都越来越多了。
[DeepWalk] DeepWalk- Online Learning of Social Representations
DeepWalk是一种简单的Graph Embedding,根据随机游走策略在图中采样得到序列,之后直接套用word2vec即可。
- random walk:沿着给定节点深度优先搜索,可以访问已经访问过的节点,直到满足序列长度要求
- 套用word2vec
- 采样策略random walk代码可以参考:python代码
[Node2vec] Node2vec - Scalable Feature Learning for Networks (Stanford 2016)
Node2Vec与deepwalk相比,只是采样策略不同,Node2Vec是对deepwalk的改进,其游走方式结合了深度优先搜索和广度优先搜索。采样得到序列后,依旧采用word2vec训练即可。
假设当前游走经过(t, v),给定当前顶点v,我们需要计算访问下一个顶点 x 的概率
- Random Walk 概率
- 在当前节点v的情况下,访问下一个节点x的概率如下
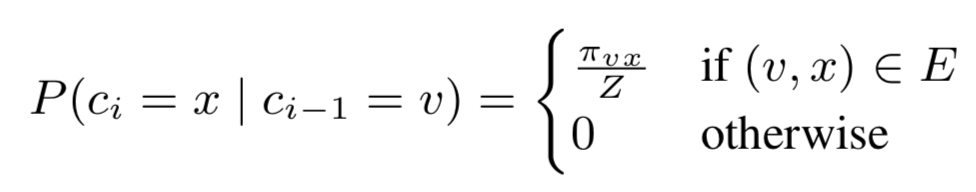
- 其中πvx代表v和x之间的转移概率(后面会介绍)
- Z是归一化因子
- 不存在边的节点之间不会存在游走,即概率为0
- 转移概率:πvx 计算 v->x 的转移概率
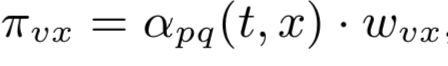
- w是节点v和x之间的权重
- 重点在于α(t,x)的计算
- α(t,x)的计算

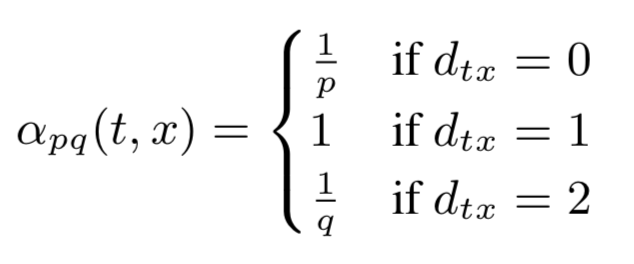
- 距离d的定义
-
- d=0: 访问刚刚访问过的节点v
-
- d=1: 访问v的邻居(广度优先)
-
- d=2: 访问x的邻居,v的邻居的邻居(深度优先)
- 参数 p
-
- 控制访问“已经访问过”的节点的概率
-
- p<1: 则α>1 更有可能访问“已经访问过的节点”
- 参数 q
-
- 控制深度优先的程度
-
- q<1: 则α=1/q 大于 1(广度优先的α),那么则是深度优先搜索
-
- q>1: 则α=1/q 小于 1(广度优先的α),那么更倾向于广度优先
[LINE] LINE - Large-scale Information Network Embedding (MSRA 2015)
- Line定义了顶点之间的一阶和二阶相关性

- 一阶(只能无向图,无法有向图):节点相似性,相邻节点的相似,如上图中的6和7直接相连,则是一阶相似
- 二阶(有向无向都可以,因为无向边可以看成两个方向相反的有向边):邻居相似性,如果A和B具有相似朋友圈,那么A和B则相似。如上图中的5和6具有相似的邻居,则是二阶相似
- 一阶和二阶分开训练,最后将两个embedding concat到一起
-
两个向量:在二阶的计算中,每个顶点对应两个向量,一个代表自身顶点向量,另一个代表该顶点作为context时的向量,这两个向量都要随着网络更新。
- 边采样 Edge Sampling
在目标函数中存在w(边权重),在梯度下降中这个w会乘在参数更新中,由于权重之间存在较大差距,导致学习率很难控制- 学习率大:可能导致梯度爆炸
- 学习率小:可能导致梯度小时
因此去掉权重w,取而代之的是对边进行采样,而采样的概率于w成正比,这样就可以解决上述问题 采样方法是Alias Method,一种利用空间换时间的方法,时间复杂度较低。
- negative sample
和word2vec类似,line也采用负采样方法,从而目标函数如下:

[SDNE] Structural Deep Network Embedding (THU 2016)
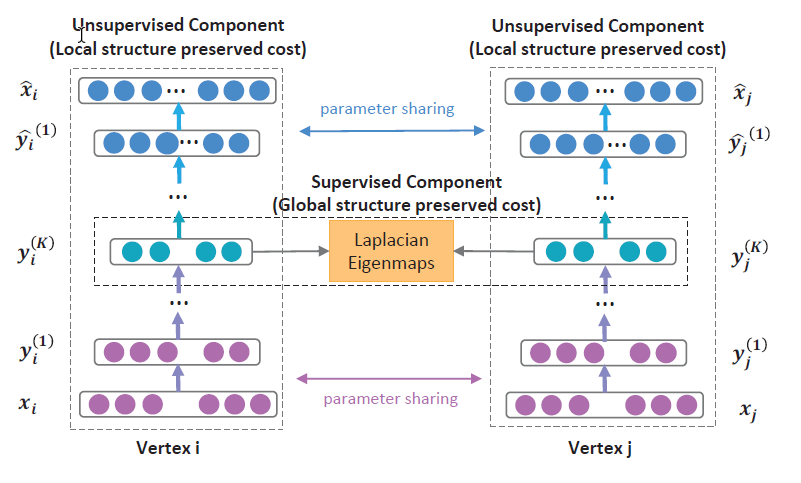
- 自编码器:x->x’网络的输出逼近网络的输入,自编码器是一种致力于重构x的网络结构
- 顶点表示:顶点x的向量表示类似于onehot,向量长度就是网络节点数量 [1, 0, 0, 1, 0, …, 0, 1],1代表该节点是x的邻居,0代表不是邻居
- 二阶损失L2nd:自编码器的重构误差 x->x’的重构误差

- 一阶损失L1st:两个节点的嵌入向量之间的加权距离。自编码器的中间层表示x的嵌入向量,代表x的关键特征。如果两个节点i和j很相似(即边权重s很大),但是他们的嵌入向量之间距离很大的话,则应该对其进行惩罚,因此定义如下损失函数:

- 正则项Lreg:对自编码器的权重进行正则:
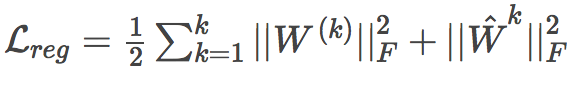
- 损失函数:三个损失汇总
[DeepWalk + side information] Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba (Alibaba 2018)
阿里巴巴针对deepwalk进行改造,在item本身embedding的基础上,融合side information,比如类目、品牌等信息。
- GES:每个item对应多个向量item_embedding,category_embedding,brand_embedding,price_embedding 等 embedding,将这些 embedding 求均值 代表最后的 item embedding
- EGES:对每个side information的embedding赋予一个权重α,之后多个side embedding的加权融合作为最后的item embedding:
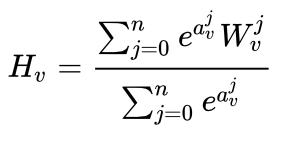
-
- 并没有直接用α加权,而是套了一层softmax
-
- α随着网络进行更新学习
-
- side information可以缓解冷启动问题
四、深度网络
DSSM
- 模型结构:两侧分别对user和item特征通过DNN输出向量,并在最后一层计算二个输出向量的内积
- 损失函数可以采用:negative sample
- 一种通用框架,源于搜索领域

[Youtoube Deep] Neural Network for YouTube Recommendation

- 训练
- 多层神经网络之后接softmax层,输出所有候选集的概率分布
- 最后一层网络输出作为user embedding
- softmax层的网络参数 作为 item embedding
- 线上:根据user和item embedding直接利用faiss找到最相似的Top-k item。
- 关键点:利用最后的网络参数作为item embedding,很巧妙
Multi-Interest Network with Dynamic Routing模型
- training
与Youtube类似,user embedding不再是一个,而是多个,代表多方面兴趣,最后利用label-aware attention,Q是item embedding,K和V是user embedding。item embedding和每个user embedding计算sore,之后对多个user embedding加权得到最后的user embedding向量,并与item embedding点乘后softmax - serving
每个兴趣向量embedding都可以与item embedding计算距离,我觉得可以自己根据业务场景和效果来自己决定加权计算的方式,比如mean或者max
五、Graph Neural Networks
GCN GAT GraphSage 未完待续。。。