损失函数(Loss Function)相关总结
常见的损失函数,如交叉熵损失、平方误差损失、Hinge损失等并不是本文的重点,关于这些损失函数的介绍网上很多,可以参考如下几篇文章
本文的重点在于总结损失函数在应用上的一些trick和技巧
单任务
相对于多任务学习而言,我们常见的模型大部分都是单任务学习,只有一个学习目标(loss)
一、标签平滑(Label Smoothing)
1. 什么叫标签平滑
正常模型的正样本标签为1,负样本标签为0,这是一种hard的学习,这样的模型可以叫做过于自信的模型。标签平滑就是将正样本的标签为0.9,负样本的标签为0.1,这是一种soft的学习,也就是让告诉模型,不要这么自信。当然标签平滑的程度可以根据情况修改。
2. 标签平滑的作用
在论文When Does Label Smoothing Help?中,作者说明标签平滑可以提高神经网络的鲁棒性和泛化能力。
3. 标签平滑的禁忌
在知识蒸馏中的教师网络中,采用标签平滑的话会影响效果,导致教师网络无法有效传递知识。
二、样本不平衡
- 样本不平衡在真实业务场景普遍存在,在数据角度可以通过过采样和抽样等方法来缓解。
- 在模型角度,可以通过损失函数的设计进一步缓解样本不平衡问题,以cross entropy 为例
普通的ce损失:
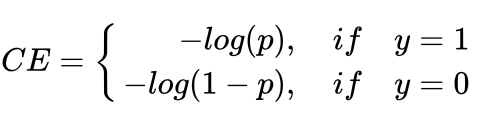
通过一个参数alpha来调节ce损失:

通过alpha来增大正样本的权重,缓解正样本少的问题。
三、难易不平衡
在样本中,必然存在一些样本容易学习(特征鲜明),一些样本较难学习。如果易分样本占据多数,那么损失函数就会被容易样本主导,对难分样本的学习能力较弱,从而影响模型的学习效果。
1. Focal Loss
假设:易分样本(置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本
focal loss的思想很简单:降低易分样本的损失,提高难分样本的损失:

假设: lambda取2时,p=0.968,那么(1-p)2=0.001,也就是易分样本的损失衰减了1000倍。
2. GHM(gradient harmonizing mechanism)
首先Focal Loss存在很多问题
- 关注难分样本:如果样本中存在离群点,Focal Loss过分关注离群点,那么模型就跑偏了。
- labmda是超参数,全靠经验
GHM不是根据样本的难易程度来进行衰减,而是根据(一定梯度内)的样本数量进行衰减,也就是谁的样本数量多,就衰减谁。
-
首先定义梯度模长g:g= p−p* ,那么g是怎么来的呢,和梯度有什么关系呢?

-
g正比于检测的难易程度,g越大则检测难度越大,可以看到,其实g就是梯度的绝对值(模长)。
-
下图是不同梯度模长g的样本数量分布

- 最左侧样本是易分样本,最右侧是难分样本,两者占比都较大,因此都要进行相应的衰减。
- 具体衰减方式:将g分桶,统计数量,之后定义梯度密度GD(g),根据GD的倒数来进行衰减。具体可以参考论文
多任务
一、总结
多任务损失函数如何确定,以及如何进行融合,一直都是一个难点。
此处主要参考Deep Multi-Task Learning – 3 Lessons Learned by Zohar Komarovsky of taboola,总结如下:
- 多个损失函数直接融合:简单求和与加权求和比较常用
- 简单求和(简单)
- 加权求和(权重难确定)
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics通过不确定性(uncertainty)来调整损失函数对应的权重。
- 多个任务通过神经网络连接:任务A的输出作为任务B的输入特征
- 前向传播:比较简单,和普通网络一样
- 后向传播:B的梯度不向A传递。
- 不同loss对应不同learning rate
- 不同的任务往往需要的learning rate的数量级不一样
- 以relu为例,learning rate较大则会出现dying relu问题,learning rate较小的话就会导致收敛很慢。
- 多任务中,对不同的损失函数设置不同的learning rate 可以一定程度缓解。
二、举例
- Deep Interest Evolution Network for Click-Through Rate Prediction:
这是阿里的一篇ctr论文,这里并不是在最后的输出层增加loss,而是在网络中间部分的GRU中引入辅助loss。

- 损失函数融合:L = Ltarget + α ∗ Laux,超参数加权的方式
- 这是一篇阿里的文章,标准的multi-task,两个网络分别对应不同的loss

- 文章根据cvr和ctr的关系,定义了post-view click- through&conversion rate (CTCVR)

- 不直接优化cvr,而是针对ctr和ctcvr的multi loss 进行优化
- ctr和ctcvr简单求和的方式

## 其它 ### 一、负采样 negative sample ### 二、sampled softmax 未完待续